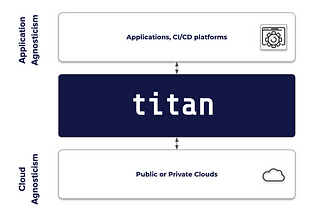
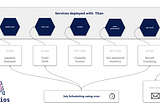
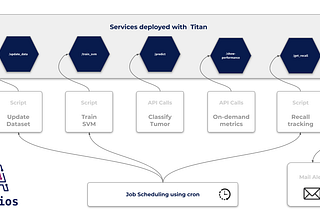
AkoiosBuilding a NLP solutionTitan Tutorial #13: A NLP Toolkit using HuggingFace, Titan and No-Code tool.Jul 22, 2021Jul 22, 2021
AkoiosCombining Jobs, Services and CITitan Tutorial #12: Building a production-ready ML pipeline to predict hotel cancellationsMay 28, 2021May 28, 2021
AkoiosIntroducing Titan JobsTitan Tutorial #11: Building a “batch-mode” churn prediction modelJun 2, 2020Jun 2, 2020
AkoiosUsing Titan with CI/CD toolsTitan Tutorial #10: A basic pipeline for Machine LearningMay 5, 2020May 5, 2020
AkoiosA first approach to MLOps using TitanTitan Tutorial #9: Integrating and consuming services in a healthcare use caseApr 28, 2020Apr 28, 2020
AkoiosBuilding a movie recommender systemTitan Tutorial #8: Building and deploying a a collaborative-filtering recommender service from scratchApr 19, 2020Apr 19, 2020
AkoiosSentiment Analysis in TwitterTitan Tutorial #7: Building and deploying a basic Sentiment Analysis modelApr 5, 2020Apr 5, 2020
AkoiosService versioning and rollbacksTitan Tutorial #6: Managing service versions for a price prediction modelMar 17, 2020Mar 17, 2020
AkoiosProvisioning environments in TitanTitan Tutorial #5: Defining deployments straight from a Jupyter NotebookFeb 26, 2020Feb 26, 2020
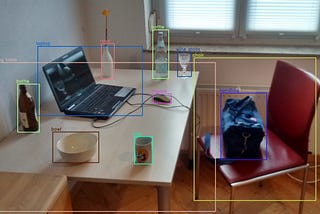
AkoiosCreating an scalable object detection service using TitanTitan Tutorial #4: Deploying an object detection model based on YOLOFeb 13, 2020Feb 13, 2020